z-anonymity: Zero-Delay Anonymization for Data Streams
-
- Contributors: Nikhil Jha, Thomas Favale, Luca Vassio, Martino Trevisan, Marco Mellia
- Year: 2020
- Venue: Proceedings of the 2020 IEEE International Conference on Big Data (Big Data)
- Abstract:
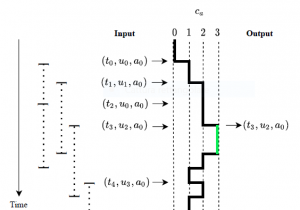
With the advent of big data and the birth of the data markets that sell personal information, individuals’ privacy is of utmost importance. The classical response is anonymization, i.e., sanitizing the information that can directly or indirectly allow users’ re-identification. The most popular solution in the literature is the k-anonymity. However, it is hard to achieve k-anonymity on a continuous stream of data, as well as when the number of dimensions becomes high.In this paper, we propose a novel anonymization property called z-anonymity. Differently from k-anonymity, it can be achieved with zero-delay on data streams and it is well suited for high dimensional data. The idea at the base of z-anonymity is to release an attribute (an atomic information) about a user only if at least z – 1 other users have presented the same attribute in a past time window. z-anonymity is weaker than k-anonymity since it does not work on the combinations of attributes, but treats them individually. In this paper, we present a probabilistic framework to map the z-anonymity into the k-anonymity property. Our results show that a proper choice of the z-anonymity parameters allows the data curator to likely obtain a k-anonymized dataset, with a precisely measurable probability. We also evaluate a real use case, in which we consider the website visits of a population of users and show that z-anonymity can work in practice for obtaining the k-anonymity too.
- Repository link: http://hdl.handle.net/11583/2878858
- Download: PDF file