PIMCITY DEVELOPMENT KIT
We identify the following fundamental components (PDK) that are necessary for building PIMS.
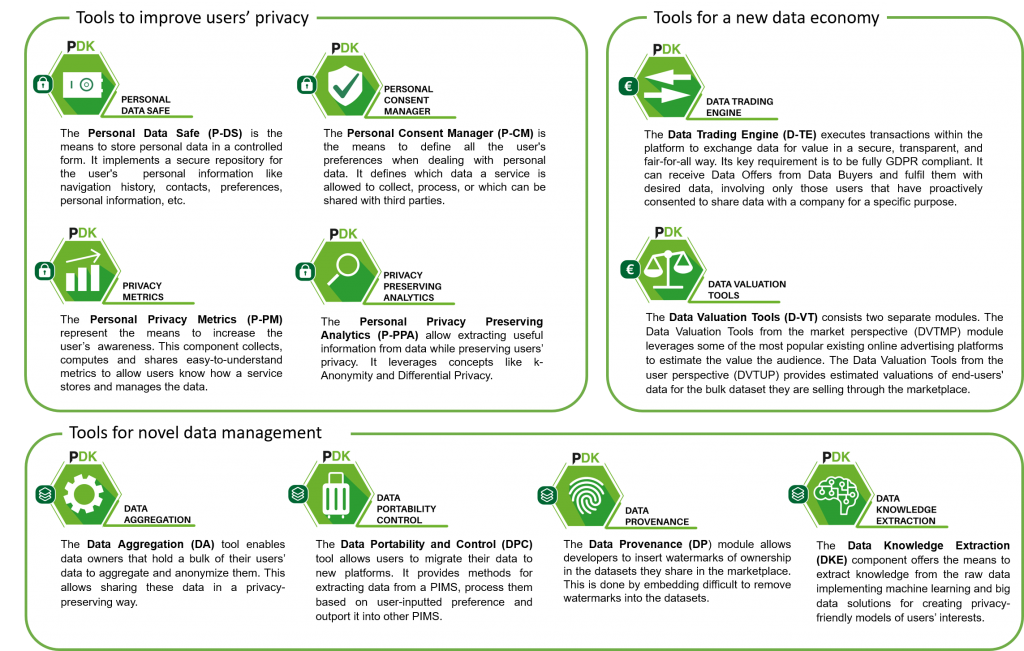
The tools that make up the PIMCITY DEVELOPMENT KIT (PDK) are Privacy Metrics, Personal Data Safe, Personal-Consent Manager, Privacy Preserving Analytcis, Data Valuation Tools, Data Trading Engine, Data Aggregation, Data Portability Control, Data Provenance and Data Knowledge Extraction.
All these basic components will provide anyone the chance to build new PIMS and integrate modules in existing solutions. Open APIs enable communications and interactions among components, easing integration of existing PIMS, as well as the design and introduction of new ones.

Elements to improve data subject privacy
Functionalities that allow the users to take informed decisions about which information to share and with whom
Personal Data Safe (P-DS)
It is the means to store personal data in a controlled form. It implements a secure repository for the user’s personal information. It is responsible for storing and aggregating user’s information such as navigation history, contacts, preferences, personal information, etc. This can be done in Push or Pull mode, i.e., the user can actively decide which information to store and retrieve; or the system can do it automatically by importing information as the y are collected while the user performs his usual activities like browse the web or move about a city. P-DS can store either the original copy of user data or point to other repositories, e.g., to external services that have already collected the data, limiting data replication if desired.
Personal Privacy Metrics (P-PM)
It is the means to increase the user’s awareness. It collects, computes and shares easy to understand novel privacy metrics. Which information the system is collecting, how it stores and manages the data, if it shares it with third parties, etc. are all fundamental information for a user to know to take informed decisions. The PM computes and offers this information via a standard interface, offering an open knowledge information system which can be queried using a open and standard platform. We will use state of art methodologies to automatically compute the privacy metrics, using supervised machine learning and artificial intelligence approaches, where domain experts, volunteers, and contributors collaborate to populate the information.
Personal Consent Manager (P-CM)
This is the means to control personal data. It is the means to define once and for all the user’s privacy policies for consent management. It defines the policies the users desire to apply when sharing personal data with services. In details, it defines which data a service is allowed to collect by managing explicit consent. Today, each site, service, apps, etc. asks for permissions to collect pieces of information about the user. The P-CM will offer standard means to share policies defined by the user with services, so to automatically and seamlessly enforce them on all platforms the user has access. Policies will be defined once for all, and imposed on all participating systems. Policy definition will be simplified, targeting not experts, via collaborative filtering approaches to provide simple suggestions and guide user’s choices.
Personal Privacy Preserving Analytics (P-PPA)
These are the means to impose control of personal data. Privacy is a must. When exchanging pieces of information with systems, we need the ability to know and control which data we are exposing. Concepts like Zero Knowledge, Differential Privacy, K-Anonymity are well known in the cryptography and privacy community. PIMS must offer and leverage these capabilities so that data can be exchanged among different systems while preserving the actual information as private. The PPA will offer standard and open implementation of these fundamental methodologies. We build on state of art, and commoditizing it so that any PIMS based on the PDK can easily integrate privacy preserving analytics

Mechanisms for the new data economy
Fundamental for PIMS is the creation of a transparent, open and easily accessible data market.
Data Valuation Tools (D-VT)
It is the means to give personal data the right value. Online systems make money with users’ personal data. It is thus fundamental to know what the economic value of each piece of information is, to let the user take informed decision on what to share, at what price. The D-VT consists in a set of methodologies that will make the value of the data transparent. It will offer standard mechanisms to publish prices, complemented with machine learning approaches to extend the knowledge to other data and systems. This information will be stored in open repositories, so that PIMS can easily give the right value to data.
Data Trading Engine (D-TE)
it is the means to monetize personal data. Often referred as Data Broker, it accesses the information stored in users’ PDRs, select those pieces to be shared according to policies defined in the CM by the user, and offer this to services in a standard way. The D-TE implements one-to-one matches between users and services based on features and incentives specified by users. It is the means to exchange desired information between users and services. It is responsible for conducting the actual data-trading transactions, whereby personal data users want to share are offered to services in exchange of rewards.
![]()
Novel Data Management Tools
Data needs to be exported, imported and exchanged using standard mechanism, with proper metadata that let the system know data source, data value, and facilitates the data aggregation from heterogenous sources
Data Aggregation (DA)
It is the means to integrate and aggregate data coming from different sources. When online, each system manages some piece of data that refer to the same user. Integrating and aggregating this data is fundamental to control/modify it. The DA offers functionalities that allow the data fusion in a seamless way, matching the same datum on different platforms, identifying and consolidating inconsistencies (same data with different values), etc. We will leverage methodologies coming from data mining, and in particular for data pre-processing, to offer simple and easy means to aggregate data from different sources. When coupled with the PPA, data remains private.
Data portability and control (DPC)
It is the means to manage the personal data a platform manages. Exporting the data from a system and importing it in another is today simply impossible. Similarly, controlling and revoking the authorization of accessing data is also fundamental to retain control on personal data. The DPC offers standard mechanisms (via flexible schema matching) to export/import data using a common superset of entities. Designed to be flexible and easy extensible, the DPC offers also basic functionalities to control the access to data.
Data provenance (DP)
It is the means to control, verify and certify the original and provenance of the data. Tracking the data downstream is very important to keep control of the data. Technology here is still immature. Watermarking is a best practice to embed the author of an image to be identified and verified. Generalizing this to other type of data is not trivial. The DP component offers state-of-art and novel solution to this problem, based on consistent fuzzy hashing or cuckoo filters. It allows one to identify the provenance of the data, even in presence of tampering or actions that try to evade identification mechanisms.
Data knowledge extraction (DKE)
It is the means to extract knowledge from the raw data. One of the biggest challenges in big data and machine learning is the creation of value out of the raw data. When dealing with personal data, this must be coupled with privacy preserving approaches, so that only the necessary data is disclosed, and the data owner keeps the control on it. The DKE consists of machine learning approaches to aggregate data, abstract models to predict future data (e.g., predict user’s interest in recommendation systems), fuse data coming from different source to derive generic suggestions (e.g., to support decision by users, providing suggestions based on decisions taken by users with similar interest).
Being PIMCity an Innovation Action, we plan to leverage as such as possible existing technologies and embracing the state of art solution, without large investment in new solutions. For this, we carefully selected SME (ERMES, TAPTAP, WIBSON) that already have working solutions, and experience in the field. Some of the key components for PIMS are not yet mature, and some of the fundamental problems to be solved have not arrived at a final solution. For this, PIMCity partners will pursue the necessary research activities when necessary.